MPEG-4 Visual
Rectangular
1 Introduction
ISO/IEC 14496-2 specifies a video codec which allows efficient compression of rectangular (frame-based) video. Support is given for manifold applications, ranging from extremely low rates and resolutions as required by mobile video transmission up to high rates, resolutions and fidelity as applicable in the field of professional production. Additional functionalities such as scalability and error resilience are supported as well.
2 Technical Solution
The video coding algorithm used for frame-based video is based on proven technology from previous standards (e.g. block-based motion compensation, DCT), including tools for functionalities such as scalability and error resilience are specified as well. MPEG-4 defines encoding of video objects, which in this case have rectangular shape. Several objects can be combined in a scene, e.g. for picture-in-picture overlays. A video object relates to the syntax and semantics of a Video Object Plane (VOP), which in this relates to a rectangular-plane frame area. Motion-compensated prediction processing is defined for B-VOP (bi-directional predictive VOP) and P-VOP (unidirectional predictive VOP). Within an I-VOP (intraframe encoded), no reference is taken to other VOPs; which, rather than using interframe prediction, use prediction within the same VOP of DC transform coefficients and the first row or column of AC transform coefficients.
2.1 Formats Supported
The following formats and bit rates are be supported by MPEG-4 Visual:
- Bit rates: typically between 5 kbit/s and more than 1 Gbit/s
- Progressive as well as interlaced video
- Different color sampling formats (including 4:2:0, 4:2:2 and 4:4:4)
- Resolutions: from sub-QCIF to 'Studio' resolutions (4k x 4k pixels)
2.2 Compression Efficiency
New compression tools are defined to improve the compression efficiency over the previous standards MPEG-1 and MPEG-2, and to support high compression performance for all addressed bit rates. This includes the compact coding of textures with a quality adjustable between "acceptable" for very high compression ratios up to "near lossless". The basic compression algorithm is hybrid coding (combination of motion-compensated prediction and scalar-quantized DCT coefficient coding). Specific tools include:
- Quarter-pixel accuracy and variable block size (8x8 or 16x16) can be used in motion compensation;
- Global motion compensation, which allows to express e.g. the effect of camera motion by using only a small number of parameters;
- Different VLC tables can be selected where the codes are designed for more efficient encoding at ranges of lower or higher rates; the choice is controlled by the encoder and can depend on the target rate;
- In the short header mode, bitstream-level compatibility with the H.263 baseline syntax is realized;
- The direct mode can determine the motion vectors within B-VOPs by inference from the co-located P-VOP motion vectors without rate overhead;
- For high-quality studio storage and inter-studio transmission applications, a different method of DCT coefficient encoding is introduced[1]. This is based on grouping of DCT coefficients by similar amplitude values instead of the conventional zig-zag run-length and level combination entropy-coding scheme. In this feature, a recursive selection of VLC tables is applied to groups of coefficients, where the selection function relies on previously coded groups. Coded data are the group indicator and a fixed-length code determining the actual coded value.
- For high-quality studio storage, a lossless coding method based on switching between DPCM and PCM is defined.
2.3 Scalability Functionalities
Complexity scalability in the encoder allows encoders of different complexity to generate valid and meaningful bitstreams for a given texture, image or video. Complexity scalability in the decoder allows a given texture, image or video bitstream to be decoded by decoders of different levels of complexity. The reconstructed quality, in general, is related to the complexity of the decoder used. This may entail that less powerful decoders decode only a part of the bitstream. More specific scalability tools defined in the video codec are as follows:
- Spatial scalability allows decoders to decode a subset of the total bitstream generated by the encoder to reconstruct and display textures, images and video objects at reduced spatial resolution.
- Temporal scalability allows decoders to decode a subset of the total bitstream generated by the encoder to reconstruct and display video at reduced temporal resolution. A maximum of three levels are supported.
- Fidelity scalability (also called SNR scalability) allows a bitstream to be parsed into a number of bitstream layers of different bit rate such that the combination of a subset of the layers can still be decoded into a meaningful signal with the same spatial and temporal resolution but lower fidelity. The bitstream parsing can occur either during transmission or in the decoder. The reconstructed quality, in general, is related to the number of layers used for decoding and reconstruction.
2.4 Robustness in Error Prone Environments
Error resilience allows accessing images and video over a wide range of storage and transmission media. This includes the useful operation of image and video compression algorithms in error-prone environments at low bit-rates (i.e., less than 64 Kbps). There are tools that address both the band-limited nature and error resiliency aspects of access over wireless networks. Specific tools for error resilience include:
- Resync markers can be embedded at different points of the bit stream, down to the level of a video packet, also called a slice, which is a unit containing a variable (defined by encoder) number of macroblocks, each of which covers a 16x16 picture region. The slice header then contains position information which is necessary to recover after data losses and restart the decoding process at the correct position in the decoded picture.
- Data partitioning allows to separate the motion data (for which a loss would be quite critical, as the reconstructed image may appear severely geometrically distorted otherwise) from the less important texture data (DCT coefficients).
- Reversible variable-length codes allow to reconstruct the DCT coefficient information backwards from a resynchronization point in the case of data errors or losses.
2.5 MPEG-4 Rectangular Video profiles and levels
The concept of profiles and levels is implemented in MPEG-4 to define conformance points of decoder configurations. Below the entity of profiles, MPEG-4 defines object types. These are combinations of tools (basic coding methods like B VOPs, interlaced coding etc.) necessary to support a selected set of applications.
One element of a profile specification is the object type, referring to a syntactical structure supporting a specific set of tools. Often the profiles and object types within them are specified in a hierarchical fashion, providing a well-defined structure for differing varieties of capability within relevant application environments. Object types related to rectangular video are as follows:
- Simple and Simple Scalable: Support for only rectangular VOPs, no B-VOPs, half-pixel accuracy of motion compensation, tools for error resilience. Simple scalable further allows spatial and temporal scalability (including B-VOPs). The Simple Profile is particularly suitable for applications on mobile networks, such as UMTS and IMT2000. Its scalable extension is useful for applications which provide services at more than one level of quality due to bit-rate or decoder resource limitations, such as Internet use and software decoding.
- Advanced Simple: A superset of the Simple object type, allowing B-VOPs, quarter-pixel accuracy of motion compensation, global motion compensation, and interlaced video coding tools. It is used in applications where higher compression performance is required than that provided by the Simple object type.
- Simple Studio and Core Studio: These are defined specifically for high resolution and high quality in applications of studio production and materials exchange. Studio-typical color sampling formats as 4:4:4 and up to 12 bit amplitude resolution are supported. Additional tools useful for production are included such as lossless coding, sprite coding and multiple alpha channels for auxiliary data.
- Advanced Real-Time Simple: Invokes additional error-resilience functionality, such as encoder/decoder re-synchronization in case of transmission errors, and resolution reduction. It is suitable for real time coding applications; such as the videophone, teleconferencing and remote observation.
- Error Resilient Simple Scalable: A superset of the Simple Scalable object type with additional error resilience tools, in particular resynchronization mechanisms for the enhancement layer.
Subsequent to the third edition of the standard text which was published in 2004, the following corrigenda and amendments are integral part of the MPEG-4 Visual specification:
- ISO/IEC 14496-2:2004/Cor.1:2004
- ISO/IEC 14496-2:2004/Amd.1:2004 (Error resilient simple scalable profile)
- ISO/IEC 14496-2:2004/Amd.2:2005 (New levels in simple profile)
- ISO/IEC 14496-2:2004/Cor.2:200X (in preparation)
3 Application areas
Frame-based MPEG-4 Video is a format that is used for efficient storage of video content and for video streaming over the Internet and mobile networks, as well as for professional applications such as video storage in studios.
Non-rectangular
1 Introduction
ISO/IEC 14496-2 specifies the coded representation of picture information in the form of natural or synthetic visual objects such as video sequences of rectangular or arbitrarily shaped pictures, moving 2D meshes, animated 3D face and body models, and texture for synthetic objects. The coded representation allows for content-based access for digital storage media, digital video communication, and other applications. The representation supports constant bit rate transmission, variable bit rate transmission, robust transmission, content-based random access (including normal random access), object-based scalable decoding (including normal scalable decoding), object-based bitstream editing, as well as special functions such as fast forward playback, fast reverse playback, slow motion, pause, and still pictures. The following description concentrates on the support for arbitrary-shaped video objects.
2 Technical Solution
The video coding algorithm is partially based on proven technology from previous standards (e.g. block-based motion compensation, DCT), but tools for new functionalities such as content-based coding are specified. While MPEG-1 and MPEG-2, are only able to encode rectangular video frames, MPEG-4 extends into encoding of video objects, which can have arbitrary shape. Video scenes can be composed from several objects which may change in position, appearance, size etc., independent of each other. For unique definition of both rectangular and arbitrary-shaped video objects in the bitstream syntax, the concept of a Video Object Plane (VOP) is introduced, which can be used to represent either a rectangular-plane frame or arbitrary-shaped object plane. Motion-compensated prediction processing is defined for B-VOP (bi-directional predictive VOP) and P-VOP (unidirectional predictive VOP). Within an I-VOP (intraframe encoded), no reference is taken to other VOPs; which, rather than using interframe prediction, use prediction within the same VOP of DC transform coefficients and the first row or column of AC transform coefficients.
2.1 Content-Based Functionalities
Content-based coding of images and video allows separate decoding and reconstruction of arbitrarily-shaped video objects. Extended manipulation of content in video sequences allows functionalities such as warping of synthetic or natural text, textures, image and video overlays on reconstructed video content. An example is the mapping of text in front of a moving video object where the text moves coherently with the object. As a specific type of video-related object, static sprites are defined, which are mosaic-like images that can geometrically be aligned by 2D global warping, such that reverse mapping into the frames of a video sequence can be performed.
2.2 Shape and Alpha Channel Coding
Shape coding assists the description and composition of conventional images and video as well as arbitrarily shaped video objects. Applications that benefit from binary shape maps with images are content-based image representations for image databases, interactive games, surveillance, and animation. A binary alpha map defines whether or not a pixel belongs to an object. It can be ‘on’ or ‘off’. ‘Gray Scale’ or ‘alpha’ Shape Coding defines the ‘transparency’ of an object, which is not necessarily uniform; it can vary over the object, so that, e.g., edges are more transparent (a technique sometimes called feathering). Multi-level alpha maps can be used to blend different layers of image sequences. Other applications that benefit from associated binary alpha maps with images are content-based image representations for image databases, interactive games, surveillance, and animation.
The binary shape mask is compressed by Context Arithmetic Encoding (CAE). Binary shape parameters are also encoded by utilization of motion information, where motion-compensated samples from the reference frame can be used within the context of CAE. As the basic concept is block-based (DCT, motion compensation), the shape is aligned with a block grid, where blocks of rectangular shape and boundary blocks of non-rectangular shape co-exist. For gray-scale shape; the encoding is performed by the same motion-compensated DCT algorithm that is used for the texture information.
Padded DCT blocks or shape-adaptive DCT can be used to encode the texture within boundary blocks of non-rectangular shape.
2.3 MPEG-4 Arbitrary-shape Video profiles and levels
The concept of profiles and levels is implemented in MPEG-4 to define conformance points of decoder configurations. Below the entity of profiles, MPEG-4 defines object types. These are combinations of tools (basic coding methods like B VOPs, interlaced coding etc.) necessary to support a selected set of applications.
One element of a profile specification is the object type, referring to a syntactical structure supporting a specific set of tools. Often the profiles and object types within them are specified in a hierarchical fashion, providing a well-defined structure for differing varieties of capability within relevant application environments. Object types related to arbitrary-shape video are as follows:
- Core and Core Scalable: Supersets of the Simple and Simple Scalable object types, respectively. These allow arbitrary binary-shape video objects, B-VOPs, and different quantization methods. The Core types are useful for applications such as those providing relatively simple content-interactivity (Internet multimedia applications).
- Advanced Coding Efficiency: A superset of the Advanced Simple object type, allowing arbitrary shaped video objects with binary or gray-scale shape. It is suitable for applications such as mobile broadcast reception, the acquisition of image sequences (camcorders) and other applications where high coding efficiency is requested and small footprint is not the prime concern.
- Main: A superset of the Core object type, invoking most of available MPEG-4 video tools such as sprites, gray-scale shape, and interlaced coding.
Subsequent to the third edition of the standard text which was published in 2004, the following corrigenda and amendments are integral part of the MPEG-4 Visual specification:
- ISO/IEC 14496-2:2004/Cor.1:2004
- ISO/IEC 14496-2:2004/Amd.1:2004 (Error resilient simple scalable profile)
- ISO/IEC 14496-2:2004/Amd.2:2005 (New levels in simple profile)
- ISO/IEC 14496-2:2004/Cor.2:200X (in preparation)
3 Application areas
Arbitrary-shape MPEG-4 Video is a format that can be used for a wide range of interactive and content-related applications, such as interactive movies and games with user-selected insertion and replacement of scene parts, insertion of segmented video objects in graphics and multimedia presentations. The different options of scene composition are also useful in editing and production of video and multimedia content.
Face and Body Animation
MPEG doc#: N7456
Date: July 2005
Author: Marius Preda (INT)
What is FBA and why is it useful?
Face & Body Animation (FBA) consists of a set of tools enabling a specific representation of a humanoid avatar and allowing very low bitrate compression and transmission of animation parameters. These features open the way of multimedia applications that allow adding in the presentations, with a reduced cost, virtual presenters. Thus, it is now possible to enrich web sites content with a human like synthetic model giving instructions to the user in an interactive way. Furthermore, it is possible to send in a television channel, multiplexed with the main video and audio streams, the animation of an avatar. Finally, but not less importantly, is the use of such tools in on-line games and 3D movies for ensuring a compact representation of the media layer.
FBA technical features
A 3D (or 2D) face and body object is a representation of the human face and body, that is structured for portraying the visual manifestations of speech, facial expressions and body posture, adequate to achieve visual speech intelligibility and the recognition of the mood and gesture of the speaker. A face and body object is animated by a stream of face and body animation parameters (FBA) encoded for low-bandwidth transmission in broadcast (one-to-many) or dedicated interactive (point-to-point) communications.
The Face Animation Parameters (FAPs) manipulate key feature control points in a mesh model of the face to produce animated visemes for the mouth (lips, tongue, teeth), as well as animation of the head and facial features like the eyes. FAPs are quantized with careful consideration for the limited movements of facial features, and then prediction errors are calculated and coded arithmetically. The remote manipulation of a face model in a terminal with FAPs can accomplish lifelike visual scenes of the speaker in real-time without sending pictorial or video details of face imagery every frame.
The Body Animation Parameters (BAPs) define joint angles with respect to body axes and are independent of a particular body model.
A simple streaming connection can be made to a decoding terminal that animates a default face and body model. A more complex session can initialize a custom face and body in a more capable terminal by downloading face definition parameters (FDP) and body definition parameters (BDP) from the encoder. Thus specific background images, facial textures, and head and body geometry can be portrayed. The composition of specific backgrounds, face and body 2D/3D meshes, texture attribution of the mesh, etc. is described in ISO/IEC 14496 part 1. An FBA stream has a maximum bitrate of 2-3kbit/s for face and 40 kbit/s for body. Optional temporal DCT coding provides further compression efficiency in exchange for delay. Using the facilities of ISO/IEC 14496 part 1, a composition of the animated face and body model and synchronized, coded speech audio (low-bitrate speech coder or text-to-speech) can provide an integrated low-bandwidth audio/visual speaker for broadcast applications or interactive conversation.
Limited scalability is supported. Face and body animation achieves its efficiency by employing very concise motion animation controls in the channel, while relying on a suitably equipped terminal for rendering of moving 2D/3D faces and body with non-normative models held in local memory. Models stored and updated for rendering in the terminal can be simple or complex. To support speech intelligibility, the normative specification of FAPs intends for their selective or complete use as signaled by the encoder. A masking scheme provides for selective transmission of FAPs and BAPs according to what parts of the face are naturally active from moment to moment.
The Face and Body Animation specifications are defined in parts 1 and 2 of the MPEG-4 standard.
Beyond FBA: the BBA specifications
In a recent work, published as ISO/IEC 14496-16, the SNHC working group, extended the FBA concepts and added a new tool called Bone-based Animation (BBA) that allows higher quality representation and animation of generic models thanks to a multilayer structure: skeleton, muscle and skin.
3D Mesh Coding
MPEG doc#: N7630
Date: October 2005
Dource: Eun-Young Chang (ETRI)
Introduction
Recently, 3D mesh models are used in various multimedia applications such as computer game, animation, and simulation applications. To maintain a convincing level of realism, many applications require highly detailed complex models. However, such models demand broad bandwidth and much storage capacity to transmit and store. To address these problems, many 3-D mesh compression algorithms have been proposed by increasing the coding efficiency for 3D models.
As one of the well-known conventional algorithms, three-dimensional mesh coding (3DMC) was introduced in MPEG-4 Visual, Version 2. 3DMC provides a representation and compression tool for IndexedFaceSet node of 3D objects onto which images and video may be mapped. 3D mesh coding is to compress static mesh models. The animation of 3D mesh models is possible by using key-frame animation (with Interpolators). 3DMC provides additional functionalities—such as high compression, incremental rendering, and error resilience—that are useful to many applications.
Technology overview
The MPEG-4 3D mesh object is a compressed bitstream of the IndexedFaceSet VRML/BIFS node. Major components in IndexedFaceSet are these:
- Connectivity: A 3D mesh consists of connected polygons. As for 2D meshes, the way to form a polygon from the given vertices is called connectivity information. Using a wireframe, it is easy to see how polygons form a 3D mesh.
- Geometry: As for 2D meshes, the 3D coordinates of the nodes or vertices are called geometry. The coordinates are represented in the Cartesian coordinate system. A basic 3D model can be generated with only connectivity and geometry information. Therefore, these two information are the most important components in 3D mesh coding.
- Other properties: In designing the appearance of the 3D mesh object, one can add colors, normals, and texture coordinates on the top of the model representation.
3DMC scheme
3DMC comprises three major coding blocks: topological surgery (data transformation); differential quantization of connectivity, geometry, and other properties (quantization); and entropy coding. In figure 1, the 3DMC decoder architecture is presented.
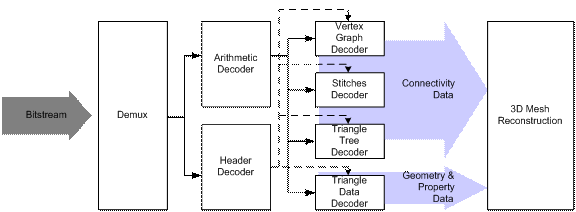
Figure 1. 3DMC decoder architecture
Functionalities
3DMC provides 30:1 to 40:1 compression ratio without noticeable visual degradation. However, compression is not the only advantage to using 3DMC. The following functionalities are supported by 3DMC:
- Compression: Near-lossless to lossy compression of 3D models is supported. Usually 30:1 to 40:1 compression ratio over a VRML ASCII file can be achieved without visual degradation.
- Incremental rendering: With 3DMC, there is no need to wait until the complete bitstream is received to start rendering it. With the incremental rendering capability, the decoder can begin building the model with just a fraction of the entire bitstream. This functionality is important when the latency is a critical issue, such as for home shopping.
- Support for nonmanifold models: Because of the compression characteristic using 3DMC topological surgery, only orientable[1] and manifold[2] models are supported. For nonorientable or nonmanifold[3] models, a dedicated operation called stitching is performed to support these models.
- Support for error resilience: With a built-in error-resilience capability, 3DMC can suffer less from network errors, as the decoder can build a model from the partitions that are not corrupted by the errors.
- Support for progressive transmission: 3D mesh models can be quite complex, with millions of polygons. Depending on the viewing distance, the user may not need million-triangle accuracy, but may be satisfied with hundreds of triangles. A scalable bitstream similar to LOD (level of detail) representation allows building 3D models with different resolutions to serve such a case.
Summary
3D mesh compression is one of the very first attempts to address compression of 3D objects. 3DMC can be efficiently used and applied with AFX tools, where 3DMC can be utilized to represent static models as well as some animated 3D models.
References
[1] MPEG SNHC Homepage, http://www.sait.samsung.co.kr/snhc.
[2] ISO/IEC 14772-1, “The Virtual Reality Modeling Language,” 1997. See http://www.web3d.org/documents/specifications/14772/V2.0/index.html.
[3] Taubin, G., W.P. Horn, F. Lazarus, and J. Rossignac, “Geometric Coding and VRML.” Proceedings of the IEEE, July 1998.
[4] Taubin G., J. Rossignac, “Course on 3D Geometry Compression.” SIGGRAPH’99, Los Angeles 1999.
[5] Jang, Euee S., “3D Animation Coding-its History and Framework.” Proceedings of International Conference of Multimedia and Expo 2000, New York. July 2000.
[6] Fernando Pereira and Touradj Ebrahimi, The MPEG-4 Book, Prentice Hall, 2002.
[7] Aaron E. Walsh and Mikael Bourges-Sevenier, MPEG-4 Jump-Start, Prentice Hall, 2002.
[8] Craig Gotsman, Stefan Gumhold, and Leif Kobbelt, “Simplification and Compression of 3D Meshes.” Tutorials on Multiresolution in Geometric Modelling, A. Iske, E. Quak, M.S. Floater (Eds.), Springer-Verlag, Hidelberg, 2002.
[1] A mesh is called orientable, iff there exists a choice of face orientations that makes all pairs of adjacent faces compatible. The orientation of two adjacent faces is compatible, iff the two vertices of the common incident edge are in opposite order.
[2] A mesh is called manifold, if each edge is incident to only one or two faces and the faces incident to a vertex form a closed or an open fan.
[3] Non-manifold meshes can be cut into manifold meshes by replicating vertices with more than one fan and edges incident to more than two faces.
[1] This and the subsequent bullet apply only for the two Studio Object Types.