MPEG-4 Reference Hardware
MPEG doc#: N 7543
Date: October 2005
Author:
Rationale of the MPEG-4 Part-9 reference HW description
Video compression standards in the never-ending search for higher and higher compression performances have reached an extremely high level of complexity. While at the very beginning of the MPEG activities the “text document” was the traditional form for the reference specification of the standard, already with MPEG-2 we have seen the appearance of non-official, but publicly available software versions. It is with MPEG-4 standardization efforts that the software description of the algorithm has become the standard description and the textual part is just provided for clarity and documentation purposes. Any possible ambiguous interpretation is solved by referring to the software description. Therefore, the generic and non-optimized software description has also become the starting point for any implementation activity of the standard. Unfortunately, working and reasoning on architectural solutions or on appropriate software/hardware (SW/HW) partitioning on several tens of thousands of lines is a very time- and resource-consuming task. In the traditional way of designing HW blocks, the full rewriting of the reference software to isolate candidate HW blocks and architectures and to generate appropriate test vectors for the correct elicitation of the designed HW system are mandatory tasks that could result in even more resource-demanding tasks than the HW design itself.
Realizing the fact that the starting point of the implementation process is too far removed from a complete implementation, two initiatives have been taken within the MPEG committee. The first is to develop a generically optimized reference software version of the standard (MPEG-4 Part 7). The second is to derive from such versions mixed SW/HW descriptions for which some parts of the reference software are described by alternative blocks described in an HDL form (MPEG-4 Part 9). Being able to support such mixed SW/HW standard description with appropriate platforms is an important and critical point for the usage and usefulness of such descriptions and is a fundamental objective of the reference HW description. The ideal architecture for such platforms includes an easily programmable board that can be plugged into a standard SW environment. Therefore, the tool needed to realize such a platform is a virtual socket that enables a truly integrated, platform-independent environment for SW and HW developments. The concept of such platform and the relation with MPEG-4 Part 7 is illustrated in Figure 1. The current platform supporting two implementations of the “virtual socket” is the WildCardII™, a PCMCIA card containing an FPGA and ZBT and SDRAM memories. With the time new more powerful platforms implementing the “virtual socket” concept and exposing the same SW and HW APIs could be used while keeping the full portability of Part 9 HDL descriptions from the old to the new platform.
In summary the aim of MPEG-4 Part-9 is to enable more widespread use of the MPEG-4 standard through reference hardware descriptions and close integration with the MPEG-4 (Optimized) Reference Software. Additionally, it is aimed that exposure to such a platform will enable a more systematic way to investigate the complexity of new codecs. The framework developed also facilitates the evaluation and benchmarking of different hardware architectures for the same MPEG-4 tools against each other. For example parallel versus serial implementations of the 8x8 DCT or different search strategies for motion estimation. In this way the properties of different architectures may be evaluated and would act as a guide to system developers.
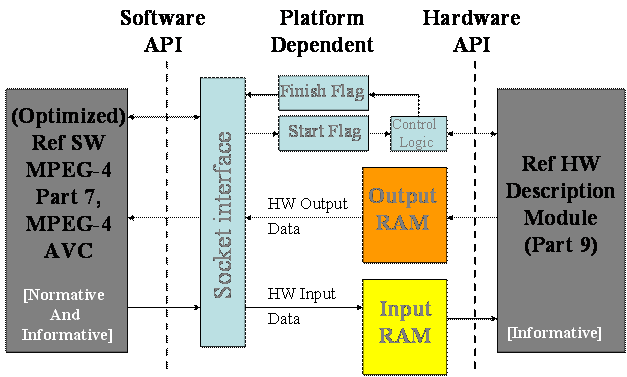
Figure 1. Relation between the modules described in a hardware description language (HDL) and the (optimized) reference SW. Part-9 is an alternative description in HDL, or in other words a conformant implementation of some “modules” of the SW description in HW.
Current HDL modules described in Part 9.
8.1 INVERSE QUANTIZER HARDWARE IP BLOCK FOR MPEG-4 PART 2
8.2 2-D IDCT HARDWARE IP BLOCK FOR MPEG-4 PART 2
A prototype code for 2D-DCT (8x8) is implemented based on one of the recently proposed architecture, called the New Distributed Arithmetic architecture (NEDA). The advantage of NEDA architecture is that it can be implemented with only adders and some shift registers at final stage.
8.3 SYSTEMC MODEL FOR 2X2 HADAMARD TRANSFORM AND QUANTIZATION FOR MPEG–4 PART 10
A SystemC emulation of the 2x2 Hadamard transform and quantization defined in the AVC standard. It is used for the coding of the DC coefficients of the four 4x4 blocks of each chroma component. The proposed architecture uses 2x2 parallel input blocks. It is designed to perform pipelined operations and it outputs a whole encoded block with each clock pulse at steady state.
8.4 VHDL HARDWARE BLOCK FOR 2X2 HADAMARD TRANSFORM AND QUANTIZATION FOR MPEG–4 PART 10 AVC
A VHDL prototype of the 2x2 Hadamard transform and quantization defined in the AVC standard. It is used for the coding of the DC coefficients of the four 4x4 blocks of each chroma component. The proposed architecture uses 2x2 parallel input blocks. It is designed to perform pipelined operations and it outputs a whole encoded block with each clock pulse at steady state.
8.5 SYSTEMC MODEL FOR 4X4 HADAMARD TRANSFORM AND QUANTIZATION FOR MPEG-4 PART 10
A SystemC emulation of the 4x4 Hadamard transform and quantization adopted by the AVC standard. It is applied to the DC coefficients of the sixteen 4x4 blocks of the luma component. The proposed architecture uses 4x4 parallel input blocks. It is designed to perform pipelined operations and it outputs a whole encoded block with each clock pulse at steady state.
8.6 VHDL HARDWARE IP BLOCK FOR 4X4 HADAMARD TRANSFORM AND QUANTIZATION FOR MPEG-4 PART 10 AVC
A VHDL prototype of the 4x4 Hadamard transform and quantization adopted by the AVC standard. It is applied to the DC coefficients of the sixteen 4x4 blocks of the luma component. The proposed architecture uses 4x4 parallel input blocks. It is designed to perform pipelined operations and it outputs a whole encoded block with each clock pulse at steady state.
8.7 A HARDWARE BLOCK FOR THE MPEG-4 PART 10 4X4 DCT-LIKE TRANSFORMATION AND QUANTIZATION
A VHDL prototype of the 4x4 forward transform/quantization adopted by the AVC standard. The proposed architecture uses 4x4 parallel input blocks. It is designed to perform pipelined operations and it outputs a whole encoded block with each clock pulse at steady state.
8.8 A SYSTEMC MODEL FOR THE MPEG-4 PART 10 4X4 DCT-LIKE TRANSFORMATION AND QUANTIZATION
A SystemC emulation of the 4x4 forward transform/quantization adopted by the AVC standard. The proposed architecture uses 4x4 parallel input blocks. It is designed to perform pipelined operations and it outputs a whole encoded block with each clock pulse at steady state.
8.9 An 8X8 INTEGER APPROXIMATION DCT TRANSFORMATION AND QUANTIZATION SYSTEMC IP BLOCK FOR MPEG-4 PART 10 AVC
A SystemC emulation of a high-performance hardware implementation of the AVC simplified 8x8 transformation and quantization. The proposed architecture uses 8x8 parallel input blocks. It is designed to perform pipelined operations and it outputs a whole encoded block with each clock pulse at steady state.
8.10 INTEGER APPROXIMATION OF 8X8 DCT TRANSFORMATION AND QUANTIZATION, A HARDWARE IP BLOCK FOR MPEG-4 PART 10 AVC
A VHDL prototype of a high-performance hardware implementation of the AVC simplified 8x8 transformation and quantization. The proposed architecture uses 8x8 parallel input blocks. It is designed to perform pipelined operations and it outputs a whole encoded block with each clock pulse at steady state.
8.11 A VHDL CONTEXT-BASED ADAPTIVE VARIABLE LENGTH CODING (CAVLC) IP BLOCK FOR MPEG-4 PART 10 AVC
A VHDL prototype of Context-based Adaptive Variable Length Coding (CAVLC). This scheme is a part of the lossless compression process in the MPEG-4 Part 10 standard. It is applied to the quantized transform coefficients of the luminance component during the entropy coding process. The design gives the encoded bitstream as an output.
8.12 A VERILOG HARDWARE IP BLOCK FOR SA-DCT FOR MPEG-4 VIS
- Serial computation scheme with multiplier-less data path
- Local clock gating based on dynamic nature of video object
- Low switching SA-DCT data alignment
8.13 A VERILOG HARDWARE IP BLOCK FOR 2D-DCT (8X8)
8.14 SHAPE CODING BINARY MOTION ESTIMATION HARDWARE ACCELERATION MODULE
8.15 A SIMD ARCHITECTURE FOR FULL SEARCH BLOCK MATCHING ALGORITHM
An efficient SIMD architecture for full search block matching algorithm is presented. The proposed architecture processes CIF format video sequences with 16x16 pixels block size and ±15 pixels search range. The proposed architecture can process more than 26 CIF frame per second. It utilizes only 16% of the hardware resources in Xilinx Virtex II FPGA XC2V3000-4.
8.16 HARDWARE MODULE FOR MOTION ESTIMATION (4xPE)
8.17 A IP BLOCK FOR AVC QUARTER PEL FULL SEARCH VARIABLE BLOCK MOTION ESTIMATION
An efficient architecture for AVC/AVC quarter pel full search variable block motion estimation is presented. The proposed architecture is capable of calculating all 41 motion vectors required by the various size blocks, supported by AVC/AVC, in parallel. The prototype is capable of processing CIF frame sequences in real time considering 5 reference frames within the search range of -3.75 to +4.00 at a clock speed of 120MHz.