MPEG-4 Advanced Video Coding
MPEG doc#: N7314
Date: July 2005
Authors: Jens-Rainer Ohm, Gary Sullivan
1 Introduction
The demand for ever-increasing compression performance has urged the definition of a new part of the MPEG-4 standard, ISO/IEC 14496-10: 'Coding of Audiovisual Objects – Part 10: Advanced Video Coding', which is identical technical content with ITU-T Rec. H.264. The development of AVC was performed by the Joint Video Team (JVT), which consists of members of both MPEG and the ITU-T Video Coding Experts Group.
2 Technical Solution
The basic approach of AVC is block-based hybrid video coding (block MC prediction + 2D block transform). The most relevant tools and elements extending over other video compression standards are as follows:
- Motion compensation using variable block sizes of size 16x16, 8x8, 16x8, 8x16, 8x8, 8x4, 4x8, or 4x4, using motion vectors encoded by hierarchical prediction starting at the 16x16 macroblock level;
- Motion compensation of the luma component sample array is performed by quarter-sample accuracy, using high-quality interpolation filters;
- Usage of an integer transform of block size 4x4 or 8x8. The transform design is not exactly a DCT, but could be interpreted as an integer approximation thereof. For the entire building block of transform and quantization, implementation by 16-bit integer arithmetic precision is possible both for encoding and decoding. In contrast to previous standards based on the DCT, there is no dependency on a floating point implementation, such that no drift between encoder and decoder picture representations can occur in normal (error-free) operation.
- Intra-picture coding is performed by first predicting the entire block from boundary samples of adjacent blocks. Prediction is possible for 4x4, 8x8 and 16x16 blocks, where for the 16x16 and 8x8 cases only horizontal, vertical, DC, and planar prediction is allowed. In the 4x4 block case, nine prediction types are supported (DC and nine directional spatial prediction modes).
- An adaptive de-blocking filter is applied in the prediction loop. The adaptation process of the filter is non-linear, with the lowpass strength of the filter steered by the quantization parameter (step size) and by syntax under the control of the encoder. Further parameters considered in the filter selection are the difference between motion vectors at the respective block edges, the coding mode used (e.g. stronger filtering is made for intra mode), the presence of coded coefficients and the differences between reconstruction values across the block boundaries.
- Multiple reference picture prediction allows to define references for prediction of any macroblock from one of up to F previously decoded pictures; the number F itself depends on the profile/level definition, which specifies the maximum amount of frame memory available in a decoder. Values around F=5 are typical when using the maximum picture size supported in the profile/level definition.
- Instead of B-type, P-type, and I-type pictures, type definitions are made slice-wise, where a slice may, at maximum, cover an entire picture.
- New types of switching slices (S-type slices, with SP and SI sub-types) allow controlled transition of the decoder memory state when stream switching is made.
- The B-type slices are generalized compared to previous standards, denoted as bi-predictive instead of bi-directional. This in particular allows to define structures of prediction of individual regions from two previous or two subsequent pictures, provided that a causal processing order is observed. Furthermore, prediction of B-type slices from other B-type slices is possible, which allows implementation of a B-frame pyramid. Different weighting factors can be used for the reference frames in the B-prediction.
- Two different entropy coding mechanisms are defined, one of which is Context-adaptive VLC (CAVLC), the other Context-adaptive Binary Arithmetic Coding (CABAC). Both are universally applicable to all elements of the code syntax, which is based on a systematic construction of variable-length code tables. By proper definition of the contexts, it is possible to exploit non-linear dependencies between the different elements to be encoded. CABAC is a coding method for binary signals, and a binarization of multi-level values such as transform coefficients or motion vectors must be performed before it can be applied; methods which can be used are unary codes or truncated unary codes (VLCs consisting of '1' bits with a terminating zero), Exp-Golomb codes or fixed-length codes. Four different basic context models are defined, where the usage depends on the specific values to be encoded.
- Additional error resilience mechanisms are defined, which are Flexible Macroblock Ordering (FMO – allowing macroblock interleaving), Arbitrary Slice Ordering (ASO), data partitioning of motion vectors and other prediction information, and encoding of redundant pictures, which e.g. allows duplicate sending or re-transmission of important information.
- Other methods known from previous standards, such as frame/field adaptive coding of interlaced material, direct mode for B-slice motion vector prediction, predictive coding of motion vectors at macroblock level etc. are implemented.
- A Network Abstraction Layer (NAL) is defined for the purpose of simple interfacing of the video stream with different network transport mechanisms, e.g. for access unit definition, error control etc.
To achieve the highest possible compression performance and other goals of the project, it was necessary to sacrifice strict forward or backward compatibility with prior MPEG and ITU-T video coding standards.
The key improvements as compared to previous standards are made in the area of motion compensation, but in proper combination with the other elements. The loop filter provides a significant gain in subjective quality at low and very low data rates. State-of-the-art context-based entropy coding drives compression to the limits. The various degrees of freedom in mode selection, reference-frame selection, motion block-size selection, context initialization etc. will only provide significant improvement of compression performance when appropriate optimization decisions, in particular based on rate-distortion criteria, are made. Such elements have been included in the reference encoder software.
The combination of all different methods listed has led to a significant increase of the compression performance compared to previous standard solutions. Reduction of the bit rate at same quality level by up to 50% or more as compared to prior standards such as MPEG-2, H.263, MPEG-4 Part 2 Simple Profile, and MPEG-4 Part 2 Advanced Simple Profile have been reported.
The concept of profile and level definitions for decoder conformance points is also implemented in the AVC standard. Presently, the following profiles are defined:
- Baseline profile: Constraint to usage of I- and P-type slices, no weighted prediction, no interlace coding tools, no CABAC, no slice data partitioning, some more specific constraints on the number of slice groups and levels to be used with this profile.
- Extended profile. No CABAC, all error resilience tools used (including SP and SI slices), some more specific constraints imposed to the direct mode, number of slice groups and levels to be used with this profile.
- Main profile: Only I-, P- and B-type slices, enhanced error resilience tools such as slice data partitioning, arbitrary slice order, multiple slice group per picture are disabled while more basic error resilience features such as slice resynchronization, NAL parameter set robustness, and constrained intra prediction are supported; some more specific constraints are made on levels to be used with this profile.
- High profile. Extending Main profile, supporting integer transform of block size 8x8 (switchable), supporting 8x8 (filtered) intra prediction modes, encoder-customized frequency-specific inverse quantization scaling, and level definitions adjusted such that better alignment with typical HD picture formats is achieved.
- High 10 profile. Extending High profile, supporting up to 10 bit amplitude resolution precision
- High 4:2:2 profile. Extending High 10 profile, extending color sampling format into 4:2:2[1].
- High 4:4:4 profile. Extending High 4:2:2 profile, extending color sampling format support to 4:4:4, supporting up to 12 bit amplitude resolution precision, supporting a residual color transform in the decoding process, and defining a transform bypass mode which allows efficient lossless coding.
A total of 5 major levels and 15 total levels (including sub-levels) is defined. Level restrictions relate to the maximum number of macroblocks per second, maximum number of macroblocks per picture, maximum decoded picture buffer size (imposing constraints on multiframe prediction), maximum bit rate, maximum coded picture buffer size and vertical motion vector ranges. These parameters can be mapped to a model of a Hypothetical Reference Decoder (HRD), which relates to buffer models and their timing behavior.
The text of the MPEG-4 AVC standard is common with ITU-T Rec. H.264. Currently, the third edition of the standard text is prepared for publication, which will contain the full set of specifications as described above.
3 Application areas
MPEG-4 AVC is expected to become widely used in a wide range of applications such as high-resolution video broadcast and storage, mobile video streaming (Internet and broadcast), and professional applications such as cinema content storage and transmission.
Scalable Video Coding
MPEG doc#: N9792
Date: April2008
Authors: Jens-Rainer Ohm, Gary Sullivan
Introduction
Scalable Video Coding (SVC) was defined as an amendment over MPEG4-AVC, providing efficient scalable representation of video by flexible multi-dimensional resolution adaptation. The interrelationship and adaptation between transmission/storage and compression technology is highly simplified by this scalable video representation, giving support to various network and terminal capabilities and also giving significantly increased error robustness by very simple stream truncation. Unlike previous solutions, SVC provides a high degree of flexibility in terms of scalability dimensions (supporting various temporal/spatial resolutions, SNR/fidelity levels and global/local ROI access), while the penalty in compression performance, as compared to single-layer coding, is almost negligible. Extensive results on subjective viewing have been presented in [1]
Technical Solution
SVC is based on a layered representation with multiple dependencies. To achieve temporal scalability, the construction of frame hierarchies is essential, where those frames that are not used as references for prediction of layers that are still present can be skipped. An example of such a hierarchical prediction structure is given in Figure 1. The pictures marked as “B3” establish the set that would be removed to reduce the frame rate by a factor of 3, by removing “B2” the frame rate would further be reduced by a factor of 2 etc.
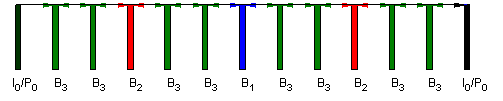
Figure 1. Example of hierarchical B prediction structure for temporal scalability.
The hierarchical prediction structure as shown in Figure 1 is not only useful to achieve the functionality of temporal scalability. Due to the establishment of finite prediction dependencies between the various frames, encoder/decoder drift problems are significantly reduced in cases where not the same information would be used for prediction on both sides due to bitstream scaling.
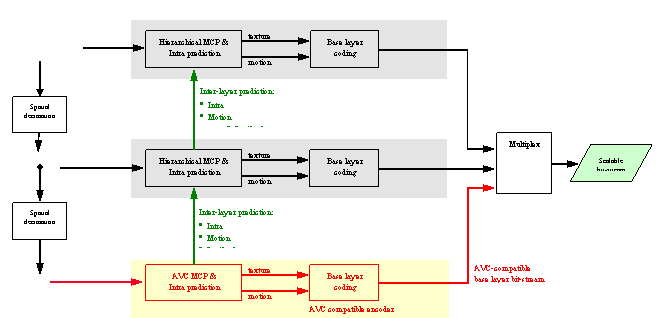
Figure 2. Hierarchical layer structure for spatial scalability
For the purpose of spatial scalability, the video is first downsampled to the required spatial resolution(s). The ratio between frame heights/widths of the respective resolutions does not need to be dyadic (factor of two). Moreover, configurations where the higher layer is 1080p and the lower layer is 720p are easily supported.
Encoding as well as decoding starts at the lowest resolution, where an AVC compatible “base layer” bitstream will typically be used. For the respective next-higher “enhancement layer”, three decoded component types are used for inter-layer prediction from the lower layer:
- Up-sampled intra-coded macroblocks;
- Motion and mode information (aligned/stretched according to image size ratios);
- Up-sampled residual signal in case of inter-coded macroblocks.
The prediction from the lower layer is an additional mode which may not always be used. In extreme case, each of the spatial layers could still be encoded completely independently, e.g. when the predictions from past or future frames of the higher-resolution layer are better than the up-sampled result from the lower-resolution layer. The different possibilities of prediction dependencies for the case of two spatial resolutions are illustrated in Figure 3.
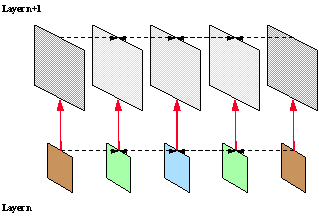
Figure 3. Example of prediction dependencies for the case of two spatial layers.
Quality scalability in SVC (also known as “SNR scalability”) can be seen as a simple case of spatial scalability, where the prediction dependencies are applied between pictures of same resolution, but different qualities. Typically, the next higher quality layer is operated by changing the AVC QP parameter by a value of 6, which maps into half quantizer step size.
Due to the nature of the information that is conveyed between the layers, it is in fact not necessary to run predictive decoder loops for the lower layers. Only information that is directly decodable, such as motion, mode, residual or intra information are conveyed to the next-higher layer. Therefore, the decoding process of SVC can be designated as single-loop decoding, which is in fact not significantly more complex than conventional AVC single-layer decoding.
Network interfaces and compatibility at base layer
At the bitstream, packetization and network interfacing level, full compatibility is retained. SVC enhancement layer information is conveyed as a new NAL unit type which would be skipped by an existing AVC decoder, such that the base layer would still be decodable by such devices. Within the SVC NAL unit header, important information about the respective packet, such as its belonging to a certain layer of spatial, temporal and quality resolution is conveyed. This can easily be extracted by media-aware network elements to make a decision on whether the respective packet should be dropped.
The compatibility with existing devices is also retained by the profile structure defined for SVC. The definitions are as follows:
- Scalable baseline profile, which builds on top of a baseline-profile base layer bitstream;
- Scalable high profile, which builds on top of a high-profile base layer bitstream;
- Scalable high intra profile, which builds on top of a high-profile base layer bitstream, but restricts the enhancement layer to intra-frame coding.
Multiview Video Coding
MPEG doc#: N9580
Date: January 2008
Authors: Aljoscha Smolic
Introduction
3D video (3DV) and free viewpoint video (FVV) are new types of visual media that expand the user’s experience beyond what is offered by 2D video. 3DV offers a 3D depth impression of the observed scenery, while FVV allows for an interactive selection of viewpoint and direction within a certain operating range. A common element of 3DV and FVV systems is the use of multiple views of the same scene that are transmitted to the user.
Multiview Video Coding (MVC, ISO/IEC 14496-10:2008 Amendment 1) is an extension of the Advanced Video Coding (AVC) standard that provides efficient coding of such multiview video. The overall structure of MVC defining the interfaces is illustrated in the figure below. The encoder receives N temporally synchronized video streams and generates one bitstream. The decoder receives the bitstream, decodes and outputs the N video signals.
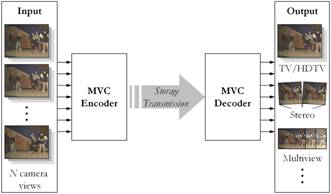
Multiview Video Coding (MVC)
Multiview video contains a large amount of inter-view statistical dependencies, since all cameras capture the same scene from different viewpoints. Therefore, combined temporal and inter-view prediction is the key for efficient MVC. As illustrated in the figure below a picture of a certain camera can not only be predicted from temporally related pictures of the same camera. Also pictures of neighboring cameras can be used for efficient prediction.
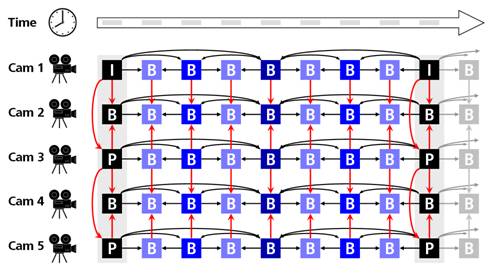
Temporal/inter-view prediction structure for MVC.
Application areas
- 3D video
- Free viewpoint video