MPEG Advanced Audio Coding
MPEG doc#: N7704
Date: October 2005
Author: S. Quackenbush
What it does:
Advanced Audio Coding (AAC) is a multi-channel perceptual audio coder that provides excellent compression of music signals while achieving transparent quality relative to a stereo Compact Disc original for audio material when coded at 128 kb/s.
What it is for:
AAC is appropriate for applications involving storage or transmission of mono, stereo or multi-channel music or other audio signals where quality of the reconstructed audio is paramount.
Description of MPEG Advanced Audio Coding
Introduction
Advanced Audio Coding (AAC) is a wideband perceptual audio coding algorithm that provides state of the art levels of compression for audio signals.
AAC is primarily available as MPEG AAC Profile technology, which comprises the AAC Low Complexity technology.
Motivation
The MPEG-2 AAC standardization effort was focused on providing EBU broadcast quality compression performance for 5-channel music signals at a total bit rate of 320 kb/s. In order to achieve this level of performance, the work item was not constrained to be in any way backward compatible with MPEG-1 audio technology.
MPEG-4 AAC incorporates MPEG-2 AAC, with the addition of the Perceptual Noise Substitution (PNS) tool.
Overview of technology
AAC achieves coding gain primary through three strategies. First, it uses a high-resolution transform (a 1024-frequency-bins) to achieve redundancy removal. This is the invertible removal of information based on purely statistical properties of a signal. Second, it uses a continuously signal-adaptive model of the human auditory system to determine a threshold for the perception of quantization noise and thereby achieve irrelevancy reduction. This is the irretrievable removal of information based on the fact that it is not perceivable Third, entropy coding is used to match the actual entropy of the quantized values with the entropy of their representation in the bitstream. Additionally, AAC provided tools for the joint coding of stereo signals and other coding tools for special classes of signals.
The following figure shows a block diagram of the AAC encoder, in which those modules that provide the primary coding gain are highlighted.
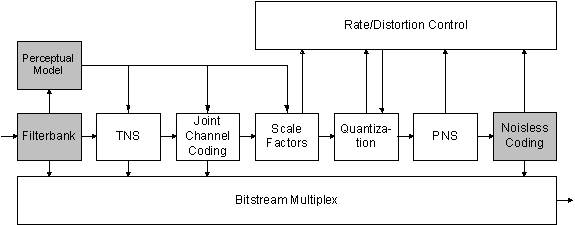
Target applications
AAC has seen considerable adoption by industry. It has application in compression for PC-based and portable devices, compression for terrestrial digital audio broadcast, streaming of compressed media for both Internet and mobile telephone channels. Additionally if functions as a core coder for other MPEG technology (i.e. HE-AAC) that has application in both satellite-delivered digital audio broadcast and mobile telephony audio streaming.
MPEG doc#: N7704, N7468
Date: October 2005, July 2005
Author: S. Quackenbush
1 Introduction
SSC is a generic audio coder employing a universal coding concept based on the most recent psycho-acoustic knowledge. The bit rate reduction techniques that are applied in this universal concept are suitable for coding both audio and speech at a competitive low bit rate. In the SSC coder four objects can be discerned. The first three constitute a monaural representation of the audio signal: Tonal, Noise and transient components. A fourth object is able to capture the stereo image.
2 Motivation
A parametric representation of an audio or speech signal inherently provides for high quality tempo and pitch scaling in the decoder for no additional cost. The parametric stereo module is coder agnostic. A powerful combination is that with HE-AAC, also standardized as the HE-AAC v2 profile.
3 Overview of technology
Until now, all high quality low bit rate audio coders are basically perceptual waveform coders, meaning that the coder attempts to reconstruct the input waveform at the decoder output as faithfully as possible, employing a perceptual quality criterion. Pure waveform coding seems to have reached the ceiling of its performance. Recent developments in high quality audio coding are the application of parametric coding techniques. A successful example is the Spectral Band Replication technology that can be combined with waveform coding. In fully parametric-based coding it is assumed that the input signal can be described as a sum of three signal components: a transient signal, a ‘deterministic’ signal and a noise-like signal. The transient signal is a sum of certain well-defined events; one might consider it a codebook of parameterised short-lasting signals. The ‘deterministic’ signal can be described as a sum of sinusoidal components.
[1] E.G.P. Schuijers, A.W.J. Oomen, A.C. den Brinker and D.J. Breebaart, `Progress on parametric coding for high quality audio.' DAGA, Aachen, 18-20 March 2003. Pp. 860-861.
[2] A.C. den Brinker, A.J. Gerrits and R.J. Sluijter, `Phase transmission in sinusoidal audio and speech coding.' 115th AES Convention, New York, 10-13 October 2003. Convention Paper 5983.
[3] 'Listening test report on MPEG-4 High Efficiency AAC v2', ISO/IEC JTC 1/SC 29/WG 11/N7137.April 2005, Busan, Korea (Public document)
4 Target applications
Language learning, games (pure parametric) and Mobile telephony, Music download (HE-AAC v2).
MPEG doc#: N7464
Date: July 2005
Author:
Introduction
MPEG-4 SBR, (Spectral Band Replication) is a bandwidth extension tool used in combination with e.g. the AAC general audio codec. When integrated into the MPEG AAC codec, a significant improvement of the performance is available, which can be used to lower the bitrate or improve the audio quality. This is achieved by replicating the highband, i.e. the high frequency part of the spectrum. A small amount of data representing a parametric description of the highband is encoded and used in the decoding process. The data rate is by far below the data rate required when using conventional AAC coding of the highband.
The Spectral Bandwidth Extension tool is combination with AAC –LC forms the High Efficiency AAC Profile, and the SBR Tool in combination with AAC-LC and the MPEG-4 Parametric stereo tool forms the High Efficiency AAC v2 profile.
The SBR tool comes in two versions, SBR-HQ (High Quality) and SBR-LP (Low Power).
Motivation
The tool enables full bandwidth audio coding at arbitrary bitrates.
Overview of technology
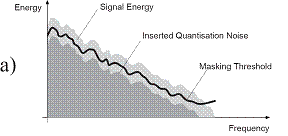
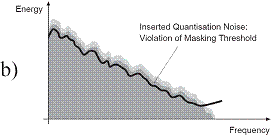
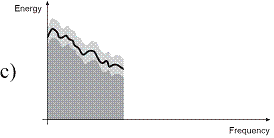
In traditional perceptual audio coding, quantisation noise is added to the audio signal. Assuming a sufficiently high bitrate, the inserted quantisation noise will be kept under the masking threshold and therefore be inaudible (see Figure 1 a). At reduced bitrates, this masking threshold will be violated (see Figure 1 b). Coding artifacts become audible. Thus, if bitrate is restricted, usually audio bandwidth will be limited (see Figure 1 c). The result will sound duller, but cleaner.
 |
 |
 |
 |
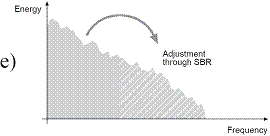 |
Figure 1, The SBR principle
With the SBR tool, the following is carried out:
- The lower frequency part (from 0 to typically 5..13 kHz) is coded using a waveform coder (called 'core codec'; e.g. one of MPEG audio codec family).
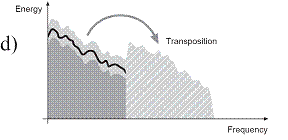
- Additionally, a reconstruction of the high frequency part happens, done by transposition of the lower frequencies (see Figure 1 d, e)
Thus, a significant bitrate reduction is achieved while maintaining good audio quality, or alternatively an improved audio quality is achieved while maintaining the bitrate.
Thus, the SBR principle stipulates that the missing high frequency region of a low pass filtered signal can be recovered based on the existing low pass signal and a small amount of control data. The required control data is estimated in the encoder given the original wide-band signal. The combination of SBR with a core coder (in this example AAC-LC as defined by the High Efficiency AAC profile) is a dual rate system, where the underlying AAC encoder/decoder is operated at half the sampling rate of the SBR encoder/decoder. The basic principle of the this encoder is depicted in Figure 2.
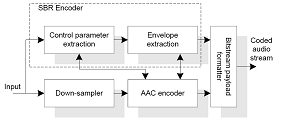
Figure 2, The SBR encoder
In the SBR encoder, where the wide band signal is available, control parameters are estimated in order to ensure that the high frequency reconstruction results in a reconstructed highband that is perceptually as similar as possible to the original highband. The majority of the control data is used for a spectral envelope representation. The spectral envelope information has varying time and frequency resolution to be able to control the SBR process as good as possible, with as little bitrate overhead as possible. The other control data mainly strives to control the tonal-to-noise ratio of the highband.
The SBR enhanced decoder can be roughly divided into the modules depicted in REF _Ref110225549 Figure
3.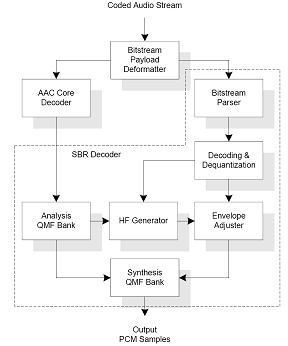
Figure 3, The SBR decoder
All SBR processing is done in the QMF domain. Hence, the output from the underlying AAC decoder is firstly analyzed with a 32 channel QMF filterbank. Secondly, the HF generator module recreates the highband by patching QMF subbands from the existing lowband to the high band. Furthermore inverse filtering is done on a per QMF subband basis, based on the control data obtained from the bitstream. The envelope adjuster modifies the spectral envelope of the regenerated highband, and adds additional components such as noise and sinusoids, all according to the control data in the bitstream. Since all operations are done in the QMF domain the final step of the decoder is a QMF synthesis to retain a time-domain signal. Given that the QMF analysis is done on 32 QMF subbands for 1024 time-domain samples, and the high frequency reconstruction results in 64 QMF subbands upon which the synthesis is done producing 2048 time-domain samples, an up-sampling by a factor of two is obtained.
Target applications
The technology is suited for any application where the full audio bandwidth cannot be sufficiently well coded by a wave-form coder. This makes it an excellent tool for application such as digital radio transmission, such as Digital Radio Mondial, digital TV transmission such as DVB, and mobile music services such as streaming and music download services, as well as internet streaming.
The following figure illustrates the performance of the SBR tool when combined with AAC-LC, i.e. the High Efficiency AAC profile. The figure is taken from the formal verification test report (WG11/N6009).
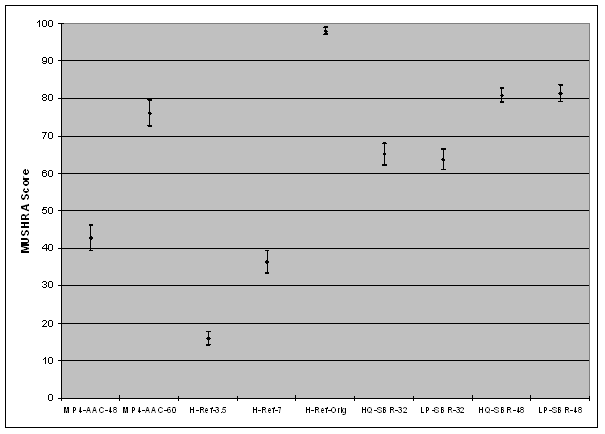
Figure 4, Test results
The test shows the performance of SBR in combination with AAC at 32kbps and 48kbps compared to MPEG-4 AAC at 48 and 60kbps. It is clear that SBR at 48kbps is equal to AAC at 60kbps, and that SBR at 32kbps is significantly better than AAC at 48kbps.
Audio Lossless Coding
MPEG doc#: N7706
Date: October 2005
Author: T. Liebchen
Introduction
Audio Lossless Coding (ALS) is a lossless audio coding algorithm that provides state of the art lossless compression for audio signals.
ALS offers flexibility in terms of compression-complexity tradeoff, ranging from very low-complexity implementations to maximum compression modes, thus adapting to different requirements.
Motivation
The ALS standardization effort was focused on providing a highly efficient and fast lossless audio compression scheme for both professional and consumer applications.
It is anticipated that a global standard will facilitate interoperability between different hardware and software platforms, thus promoting long-lasting multivendor support.
Overview of technology
The basic ALS algorithm essentially uses forward-adaptive linear predictive coding (LPC). The prediction residual is transmitted along with quantized filter coefficients. The decoder applies the inverse prediction filter in order to achieve lossless reconstruction. The following figure shows a block diagram of the basic ALS encoder.
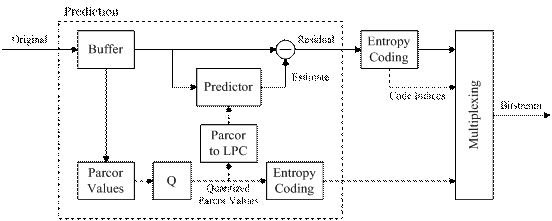
Additional tools, which can be switched on to improve compression, comprise long-term prediction (LTP) and multi-channel prediction (MCC). Alternatively, a backward-adaptive predictor (RLS-LMS) can be used instead of the forward-adaptive predictor.
Target applications
ALS is aimed at applications that require unimpaired quality at reduced data rates, including audio compression in studio operations, preservation and archival systems, as well as delivery by physical media and over computer networks.
Scalable Lossless Coding
MPEG doc#: N7707
Date: October 2005
Author: Ralf Geiger, Rongshan Yu
Introduction
MPEG-4 SLS provides a scalable lossless extension of AAC. The lossless enhancement is done in a fine-grain scalable way, allowing for signal representations from the quality of the AAC core to numerically lossless, including near-lossless signal representation. It also works as a standalone lossless coder when the AAC core is not present.
Motivation
MPEG-4 SLS is motivated by applications that require audio quality beyond perceptual transparency such as archive applications which require lossless compression, or studio operation which requires additional coding margin for post-processing or tandem coding. In addition, it is also motivated by applications that require bit-rate adaptation at transmission.
For lossless compression, the total bit-rate of the compressed bit-stream is time-varying, and signal dependent. Typically, the average bit-rate is about 768 kbps for stereo audio at 48 kHz / 16 bit (2:1 compression on average, depending on the input signal). For higher resolutions (sampling rates and word length) this bit rate increases up to about 4000 kbps stereo for 192 kHz / 24 bit signals. Consequently, there is a very large gap between the bit rates required for perceptually transparent and for lossless coding.
The MPEG-4 SLS codec fills this gap by extending the quality of the its core coder to lossless in a fine-grain scalable way, thus it provides both lossless and intermediate signal representation. This is illustrated in Figure 1.

Figure 1. Bit rate range covered by MPEG-4 SLS
Overview of technology
The SLS algorithm is a scalable transform-based coder, providing a gradual refinement of the description of the transform coefficients, starting with perceptually weighted reconstruction levels provided by the AAC core bitstream, up to the resolution of the original input signal. In order to achieve lossless reconstruction, the SLS decoder uses an inverse Integer MDCT (IntMDCT) transform, and deterministic versions of several tools used for AAC-core bitstream decoding (see Figure.2).
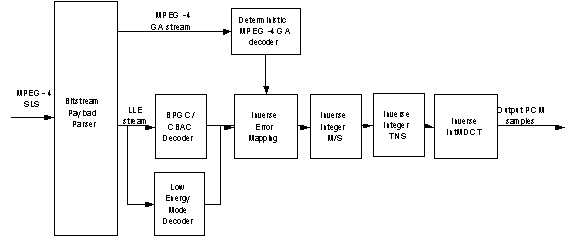
Figure 2. SLS decoder block diagram
MPEG-4 SLS can also be used as a stand-alone lossless codec without AAC core. The resulting structure is illustrated in Figure 3. In this mode, the SLS decoder has a very simple structure, mainly comprising the entropy decoder and the inverse transform. The AAC encoder and decoder are not required for this non-core mode operation. (Figure. 3)
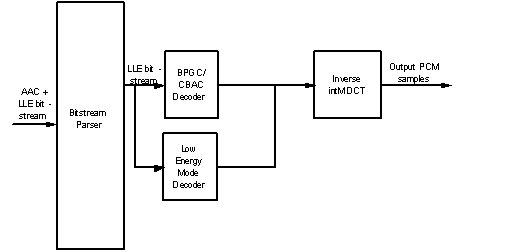
Figure 3.SLS non-core decoder block diagram
Target applications
Target applications include archiving with lossless signal representation and high-quality transmission with constant bit rate and robustness to tandem coding.
The following application scenarios motivate some of the foreseen applications:
Audio archiving
With its lossless compression capability, MPEG-4 SLS nicely fits into any applications that need lossless audio quality. Typical applications include music archival for either studio or personal users, and high-end audio applications.
The broadcast chain
In a broadcast environment, MPEG-4 SLS could be used in all stages comprising archiving, contribution/distribution and emission. This is illustrated in Figure 4. For archiving the codec can operate in a lossless way, for contribution/distribution a constant, high bit rate (e.g. 512 kbps) can be used, and finally the AAC core can be used for emission.
In this broadcast chain, one main feature of the MPEG-4 SLS architecture can be used: In every stage where no post-processing but only a lower bit rate is required, the bit stream is just truncated, and no re-encoding is therefore required.
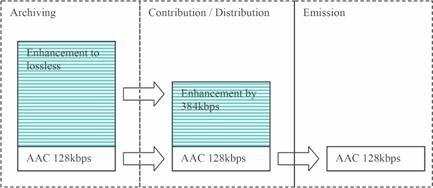
Figure 4. MPEG-4 SLS in the broadcast chain
High quality transmission at constant bit-rate
In situations where a constant rate transmission is required, SLS can provide a high near-lossless to lossless audio quality at e.g. 768 kbps stereo for 48 kHz / 16 bit, corresponding to a guaranteed compression of 2:1.
Thus is a unique feature of SLS. While pure lossless codecs can provide an average compression of 2:1 for certain test material, this compression cannot be guaranteed, and thus a transmission at a reduced constant bitrate is not possible.
Digital music distribution
In combination with AAC, MPEG-4 SLS can be flexibly fitted into the full life cycle of digital music distribution. This is illustrated in Figure 5. In this application scenario, the users can obtain SLS files either by download from a service provider, or by ripping from their own music CDs. They can then play the music at the desirable bitrate, e.g., possibly lossless quality at their living room, and low bitrate copies for their portable audio devices.
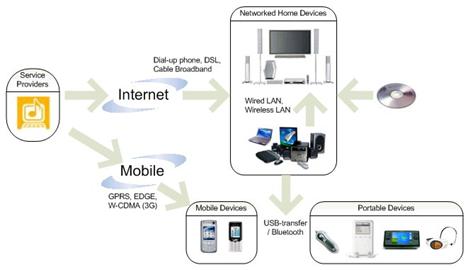
Figure 5. MPEG-4 SLS for digital music distribution
MPEG doc#: N7465
Date: July 2005
Author:
1 Introduction
With the advent of high-capacity storage media in the early nineties, the interest for high-resolution audio home delivery has significantly increased. This trend has been recognized by the music industry, and has seeded the conception of Super Audio CD (SA-CD), an audio delivery format that combines the desired ultra high audio quality with the desire to reproduce both stereo and multi-channel audio recordings. A one-bit digital storage format has been found to comply with the most demanding consumer requirements with respect to audio quality. The one-bit coding format is referred to as “DSD” (Direct Stream Digital). Although on SA-CD a data rate of 64 times 44.1 kS/s (“64 Fs”), roughly equaling 2.8 MS/s is employed, DSD also allows for higher oversampling rates of 128 and 256 times fs that are mainly used for archiving purposes.
2 Motivation
The high data rates taken by the DSD format, clearly call for a lossless compression technique, for more efficient usage of storage space. This has resulted in a lossless coding technique for one-bit oversampled data, which has been coined “DST” (Direct Stream Transfer) [1,2].
3 Overview of technology
Within the lossless encoder and decoder, one can distinguish three stages of framing, prediction, and entropy coding. The framing process divides the original one-bit audio stream consisting of samples b Î {0, 1} into frames of length 37,632 bits, corresponding to 1/75 of a second, assuming a sampling rate of 2.8MS/s. The framing provides for easy “random” access to the audio data during playback. Prediction filtering is the first necessary step in the process of (audio) data compression.
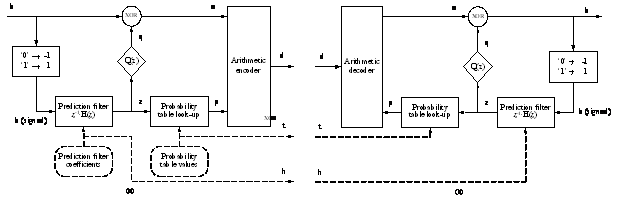
Figure 1 Schematic overview of the encoder and decoder.
The prediction filtering step, shown in more detail in Figure 1a, attempts to remove redundancy from the audio bit stream b, by creating a new bit stream e, which is not redundant. Together with the prediction filter coefficients h, error stream e carries the same information as b. It is clear that the prediction signal z is multi-bit. The prediction bits q are derived from the multi-bit values z by simple truncation, indicated by the block labeled Q(z). As becomes clear from the decoder diagram (Figure 1b), the computationally demanding design of the prediction filter is only required in the encoder. The player only has to perform the, much less demanding, decoding process, where the most expensive operation is the FIR filtering process. Since the filtering needs to be performed on a one-bit signal, the implementation is straightforward and does not pose any problems. To enable complete reconstruction of the original bit stream on the decoder side, the prediction filter coefficients and the error bits have to be transferred for each frame. The decoder calculates the original bit stream from the error bits and the predictions. When proper prediction filters are used, the signal e will consist of more zeroes than ones and can thus result in a possible compression gain. Arithmetic encoding methods can be used successfully when accurate information on the probabilities of the symbols “0” or “1” is available. By also conveying this probability information in the bitstream, "arithmetic coding" is thus able to approach the upper limit to the achievable compression. In a full encoder, every channel has its own source model (consisting of the prediction filter and probability table), whereas only a single arithmetic encoder is used. To exploit the correlation between channels, however, it is also possible to let channels share prediction filters and/or probability tables. The lossless compression performance is demonstrated with wide-band 256 Fs recordings, and 128 and 64 Fs down converted versions of these, demonstrating the scalability of the algorithm. As is illustrated in Figure 2, the compression ratio h, typically amounts to 2.7-2.8 for an sampling rate of 64 times Fs.
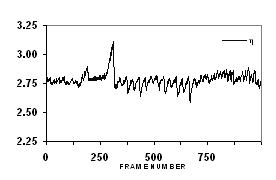
Figure 2 - Compression ratio for 1000 frames of a recording (classical music, 6 channels).
[1] Derk Reefman and Erwin Janssen, “One-bit audio: an overview”, JAES, vol. 52, no. 2, February 2004.
[2] Erwin Janssen, Eric Knapen, Derk Reefman and Fons Bruekers, "Lossless compression of one-bit audio", ICASSP 2004.
4 Target applications
Archiving and storage of 1-bit oversampled audio signals and SA-CD.
MPEG doc#: N7705
Date: October 2005
Author: Giorgio Zoia
What it is
Structured audio representations are coding schemes that are made up of semantic information about the sounds they represent and that make use of high-level models. Well-known examples of structured audio representations in literature are for instance the musical-instrument digital interface (MIDI) musical-event lists, and linear-prediction models of speech [1]. A toolset for structured general representations of sound is defined by MPEG-4, namely MPEG-4 Structured Audio.
What it is for
Among the numerous applications of structured sound, a very important one is ultra low-bitrate transmission of audio content and related processing algorithms, exploiting formerly unexplored forms of redundancy in signals. Furthermore, structured sound descriptions allow perceptually or physically sensible control, providing a more natural interface for the search and manipulation of data.
Description of MPEG-4 SA
SA shows a general concept very similar to that of the most popular SWSS sets (software sound synthesis sets, see e.g. [2] for an applied overview) typical of the world of computer music, and it is basically composed by two native tools, SAOL and SASL, plus support of two other tools: a sound bank format (SA-SBF from MIDI DLS-2) and MIDI.
Structured Audio Orchestra Language
SAOL (Structured Audio Orchestra Language) is a C-like programming language. It is used to describe an orchestra of instruments (in the wide sense, including functionality for both sound generation and sound processing) with their related functions; it only uses variables of a single numeric type (32-bit floating point). Variables are instead characterized by three different rates: initialization-, control- and sampling-rate; statements as a consequence, are each one characterized by one the same three rates and periodically executed at that rate in programming order.
Structured Audio Score Language
SASL (Structured Audio Score Language) is used to schedule tasks through instrument instantiations and control statements (affecting control-rate variables); SASL instructions can be dispatched to the decoder at any time, at the initialization of the performance and/or at the beginning of each control cycle, through an MPEG-4 stream of data. A built-in scheduler maps SASL instructions on SAOL instruments creating in runtime a program, which can be called indifferently performance or decoding (in this particular case the second term, typical of coding standards, is equivalent to the first).
MIDI support
An alternative method that can also be used (in conjunction with or instead of SASL) for control of structured audio is
In addition to SASL, MIDI score events can also be used for controlling the playing of SAOL instruments. MIDI (Musical Instrument Digital Interface) has been widely used in the music industry since its disclosure in 1983. This form of control is included in SA to enable backwards compatibility with MIDI-based synthesis. When used in algorithmic SAOL-based synthesis, the MIDI events are converted to SAOL orchestra control events before execution.
Both the MIDI and the SASL control information can be transmitted in the SA stream header and in the bitstream following it. The control events in the header (either in a MIDI file or a SASL score file) must have timing information, which is used to register each event with the scheduler of the decoder to be used later in the decoding process.
The Sample Bank Format
The Structured Audio Sample Bank Format (SASBF) is used for transmission of audio sample banks for wavetable synthesis and associated simple processing algorithms.
The SASBF is based on MIDI Downloadable Sounds 2 format (DLS 2) that like MIDI is also specified by the MIDI Manufacturers Association (MMA). The purpose of this format is to guarantee the quality of the synthesized sound and the compatibility between different decoders. In fact, general MIDI only specifies the mapping between the MIDI events and the music instruments, but it does not normatively define the quality of the music synthesis. MIDI alone enables a very low bitrate transmission of sound, but it is entirely dependent on the synthesizer concerning what the output will sound like. The downloadable sound concept in SASBF is used to transmit instead the wavetables with the bitstream, providing a normative way to control the quality of the played samples.
SA Object Types
There are four SA-based object types that can be defined in an MPEG-4 bitstream:
- In MIDI-only object type only MIDI files of MIDI events are transmitted in the bitstream. This means that the decoding uses non-normative ways to generate sound, and the mapping between the MIDI instruments and the music synthesis is done according to the patch mappings defined in the General MIDI specification. Thus a bitstream of this object type is backwards compatible with the MIDI specification.
- In Wavetable object type MIDI files and SASBF wavetables can be transmitted in the bitstream, and MIDI events are used to control playing the wavetable-based instruments.
- In Algorithmic Synthesis object type only SA native tools can be used in the bitstream; the synthetic instruments are defined only with SAOL statements and variables, while SASBF is not supported; SASL score events only can be used to control the sound synthesis process.
- In Main Synthesis object type all components of SA are allowed in the stream, including SASBF, MIDI files and events.
The following picture shows a block diagram for the most generic SA decoding process, i.e. the one allowed by the Main Synthesis object type.
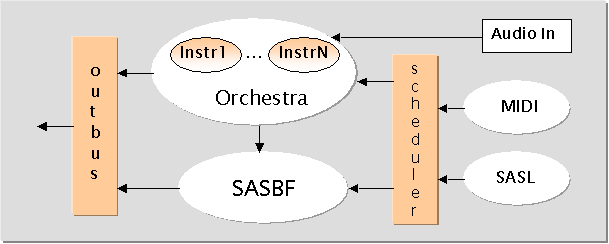
SA Application Scenarios
The versatile toolset of MPEG-4 Structured Audio enables a rich variety of applications. The main scenarios are the following:
- MIDI over MPEG-4. At the lower level, SA allows supporting MIDI specification inside a normative MPEG-4 stream or file.
- Wavetable synthesis. The wavetable synthesis engine in MPEG-4 SA offers a bounded-complexity sound synthesis implementation, and enables implementation on low-complexity decoders and terminals. Current applications may include karaoke systems, musical backgrounds for WWW pages, mobile-device tools, etc.
- Algorithmic synthesis. The algorithmic synthesis capability of SA offers high-quality user-definable sound synthesis including expressive control. Because any signal processing routine can be written with SAOL, the application area is very wide. Current applications may include generic sound synthesis and computer music, video games, low-bitrate Internet delivery of music, virtual reality models and entertainment.
- Audio effects processing. A SAOL program can be used as custom effects processing module for natural and synthetic audio.
- Generalized structured audio coding. The SA decoder can be used to emulate the behavior of natural audio coders (in essence any decoder can be implemented using SA tools). However, the SA toolset may not provide the computationally optimal tools to achieve the best general audio coding in all cases.
References
[1] C. Roads, The Computer Music Tutorial, Cambridge, MA: MIT Press 1996, parts II and III
[2] R. B. Dannenberg and N. Thompson, Real-Time Software Synthesis on Superscalar Architectures, Computer Music Journal, vol. 21 (3), pp. 83-94, MIT Press 1997
[3] J. Hupaniemi and R. Väänänen, SNHC Audio and Audio Composition, in F. Pereira and T. Ebrahimi (editors): The MPEG-4 Book, Prentice Hall PTR, 2002.